



Data Infrastructure
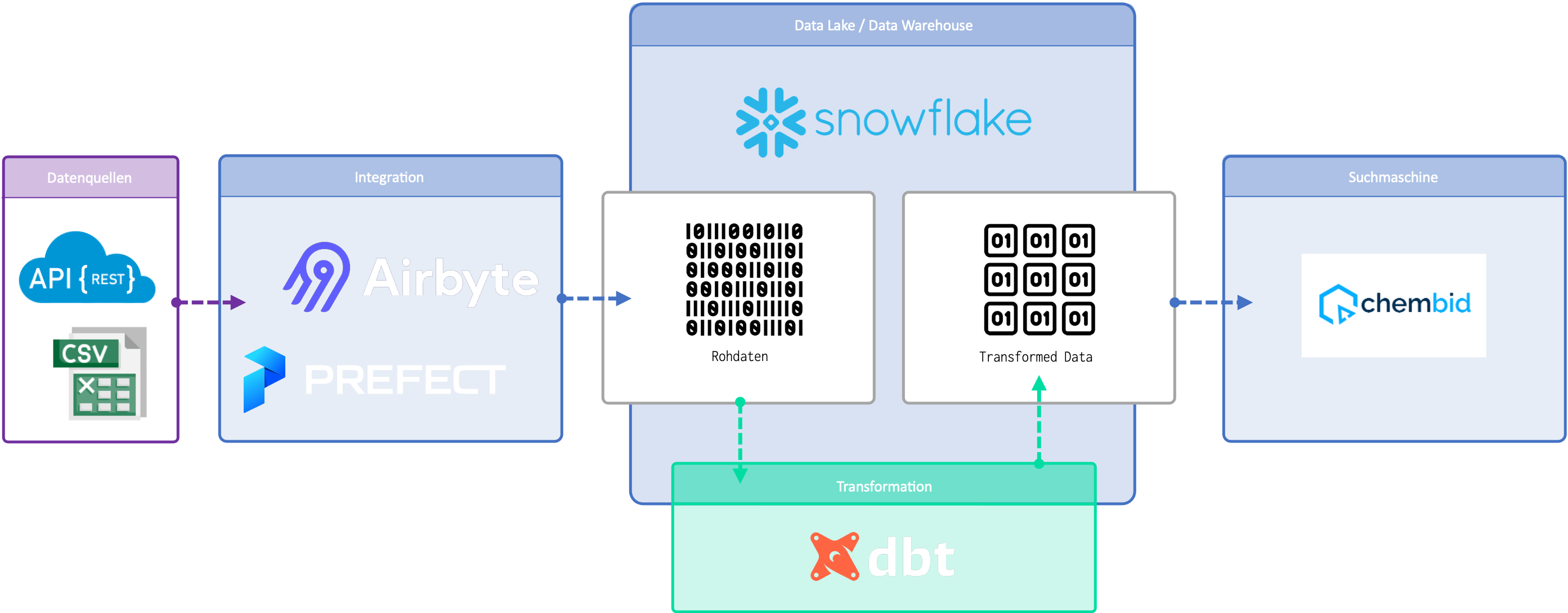
Umgekehrte Datenintegration mit Reverse ETL 🚀
Mit Hilfe von Reverse ETL gelingt es Unternehmen, automatisierte und intelligente Entscheidungen zu treffen. Von unserem Analytics Engineer Jan-Henrik erfährst du, wie Reverse ETL funktioniert, welche Vorteile es bringt und wie auch du von Reverse ETL profitieren kannst.


